.svg)
.svg)
DDMRP : différences MRP et approche IA probabiliste

Depuis vingt ans, on présente le DDMRP aux Supply Chain Directors comme le remplacement moderne du material requirements planning (MRP) classique. Les buffers stratégiques remplacent la prévision push, la gestion par exception remplace le replanning massif, le flux remplace les urgences. Tout cela est vrai. Mais ce que la communication autour du DDMRP discute rarement, c'est ce que ses buffers sont vraiment : des règles heuristiques bâties sur un facteur de variabilité et un facteur de délai, pas une mesure de distribution de demande. Cet écart compte quand votre portefeuille est creux, votre demande bruitée, ou que le taux de service doit être tenu à la référence.
En résumé : le DDMRP voit juste sur le problème du MRP. Il reste incomplet sur la réponse.
Ce guide s'adresse aux S&OP managers et aux planificateurs qui évaluent le DDMRP face à ses alternatives. Il revient sur ce qu'est le DDMRP, ce qui change par rapport au MRP, où la méthodologie s'arrête, et ce qu'une approche probabiliste apporte, avec ou sans remplacement des systèmes existants.
Pourquoi le DDMRP a émergé après les limites du MRP
Le DDMRP a été publié en 2011 par Carol Ptak et Chad Smith, les auteurs du courant Demand Driven (fondateurs du Demand Driven Institute). Il n'a pas surgi dans le vide. C'est une réponse directe aux faiblesses structurelles du MRP classique, qui sert de colonne vertébrale à la Production Planning depuis les années 1970.
Le MRP classique part d'une prévision et avance. Le système éclate un plan directeur de production à travers chaque niveau des nomenclatures (BOM). Il nette les besoins contre les stocks disponibles et recommande des ordres d'achat ou de production pour couvrir le manque projeté. La logique est rigoureuse, mais le terrain connaît deux modes de défaillance :
Le DDMRP garde la structure de la planification matière mais la découple. Au lieu de faire tourner une seule cascade pilotée par la prévision, il place des buffers stratégiques à des points choisis du réseau : références à long délai, composants communs, produits finis exposés à une demande volatile. Le réapprovisionnement est tiré depuis ces buffers, pas poussé par le plan directeur. Le modèle devient réactif à la consommation réelle tout en protégeant les opérations amont du bruit court terme.
Les 5 piliers du DDMRP
Le Demand Driven Material Requirements Planning s'organise autour de cinq piliers, définis par le Demand Driven Institute.
Le premier est le positionnement stratégique des buffers. On ne place pas des stocks tampons partout : ils s'installent aux points de découplage choisis pour leur effet de levier sur les délais, la tolérance client et la complexité des nomenclatures.
Le deuxième est le dimensionnement et profilage des buffers. Chaque buffer est calibré en trois zones (vert, jaune, rouge) à partir de la consommation moyenne journalière, du délai et d'un facteur de variabilité. Ce facteur est une hypothèse de niveau catégorie, pas une mesure à la référence.
Le troisième est l'ajustement dynamique. Les buffers évoluent avec les événements planifiés : saisonnalité, promotions, lancements de nouveaux produits. Le système recalcule les zones vert, jaune et rouge à une cadence définie.
Le quatrième est la planification axée sur la demande, exécutée par la Net Flow Equation :
Net Flow = Stock disponible + En commande - Demande qualifiéeQuand le Net Flow tombe dans la zone jaune, le système signale un ordre de réapprovisionnement. Quand il tombe en rouge, l'ordre est priorisé.
Le cinquième est l'exécution visuelle et collaborative. Les buffers sont affichés visuellement aux opérations, le plus souvent sur des tableaux de bord en code couleur, pour que les planificateurs agissent sur les exceptions plutôt que de courir derrière chaque ordre.
Ces cinq piliers font passer la planification du « faire selon la prévision » au « faire selon la consommation réelle, protégée par buffers ».
DDMRP vs MRP : ce qui change vraiment
Comparer le DDMRP et le MRP au niveau méthodologique est trivial. Les comparer au niveau du planificateur est plus utile.
Sous MRP
Dans un environnement MRP, le plan directeur fait foi. Chaque recommandation de réapprovisionnement découle de la prévision poussée à travers les nomenclatures. Quand la prévision bouge, les recommandations bougent avec elle. Le planificateur dispose d'un plan complet, mais fragile. Chaque ajustement génère une nouvelle vague d'ordres, y compris dans les périodes gelées. Il passe une part non négligeable de sa semaine à négocier avec le système pour qu'il arrête de réagir.
Sous DDMRP
Dans un environnement DDMRP, le plan directeur existe toujours, mais ce n'est plus le levier quotidien. La Net Flow Equation l'est. Les décisions de réapprovisionnement se prennent à chaque référence bufferisée à partir de la consommation réelle, de la demande qualifiée et de l'en-cours. La journée du planificateur devient pilotée par exception : il traite les références qui ont basculé en jaune ou rouge, et laisse le reste tranquille. Les délais sont découplés à travers le réseau : un retard à une étape ne se répercute plus automatiquement sur chaque ordre aval.
Ce changement entraîne deux conséquences concrètes. Les niveaux de service sur les références bufferisées deviennent plus stables, parce que les buffers dynamiques absorbent le bruit court terme que le MRP aurait propagé. Le besoin en fonds de roulement (BFR) tend à baisser sur les références où l'ancien setup MRP sur-protégeait via des marges de sécurité. Il peut au contraire grimper là où les buffers sont sur-dimensionnés aux points de découplage. Le résultat net dépend largement de la façon dont les buffers ont été positionnés et dimensionnés, et c'est plus difficile qu'il n'y paraît.
Là où le DDMRP voit juste, et là où il s'arrête
Le DDMRP voit juste sur trois points, et ils comptent.
Là où le DDMRP s'arrête, c'est sur la quantification de l'incertitude. Le facteur de variabilité au cœur du dimensionnement des buffers est une règle heuristique de niveau catégorie, pas une mesure du comportement réel de la demande à la référence. Le facteur de délai est tout aussi heuristique. La critique du DDMRP par Lokad, la plus rigoureuse publiquement, le formule sans détour. La méthode propose des recettes numériques sans le formalisme qu'une approche probabiliste exigerait. Ses hypothèses de dimensionnement peuvent se tromper de beaucoup sur les références (SKU) peu fréquentes ou erratiques.
L'écart n'est pas théorique. Il se manifeste sur les SKU les plus exposés : les références à longue traîne où les buffers heuristiques sur-protègent (capital immobilisé en stock) ou sous-protègent (ruptures sur des articles qui comptaient pour le client). Notre webinar sur le réapprovisionnement des matières premières au-delà du MRP traditionnel détaille comment cela se joue sur le terrain.
Buffers heuristiques vs prévision probabiliste : le vrai débat
Le débat intéressant en 2026 n'est pas DDMRP vs MRP. Les deux sont des méthodologies heuristiques construites avant que l'infrastructure de données nécessaire pour faire mieux ne soit largement accessible. Le débat est buffers heuristiques contre prévision probabiliste.
Comment fonctionne un buffer heuristique
Un buffer heuristique pose la question :
étant donné une demande moyenne de X par jour et un délai de Y jours, avec un facteur de variabilité de Z %, quel stock dois-je tenir ?
Il renvoie un nombre. Le nombre est défendable, mais il est aveugle à la forme de la demande. Deux SKU avec la même moyenne peuvent avoir des profils de risque radicalement différents. L'heuristique ne le voit pas.
Comment fonctionne une approche probabiliste
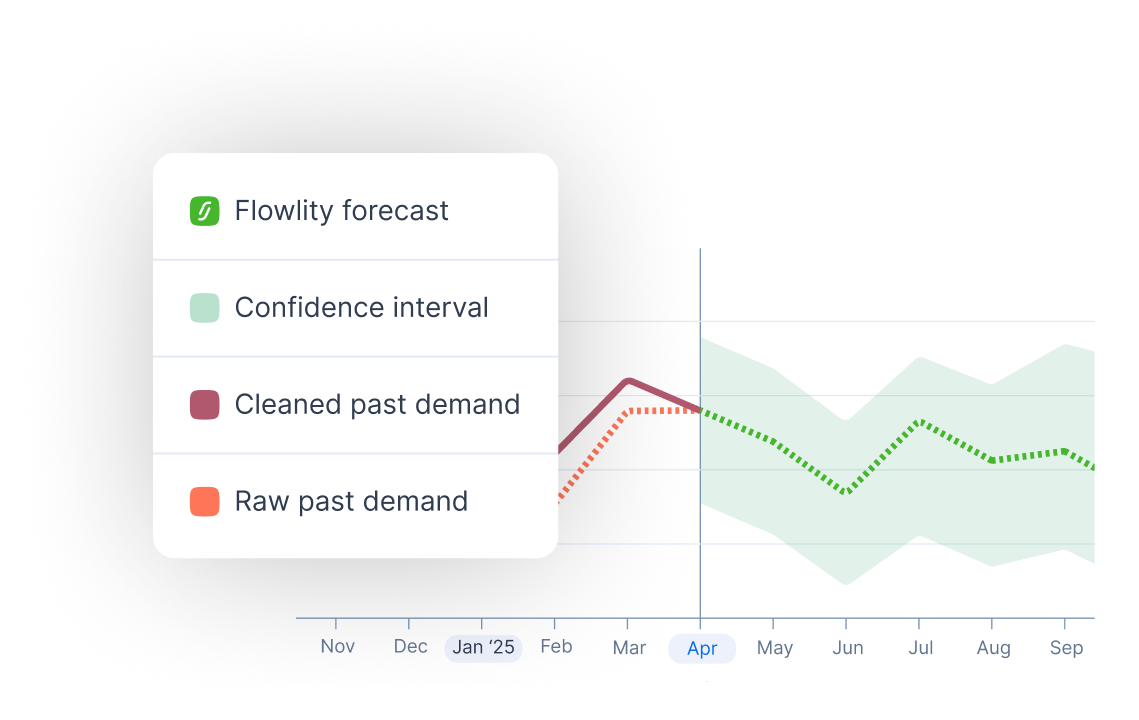
Une approche probabiliste pose une autre question :
compte tenu de tout ce que l'on sait d'une référence (historique, saisonnalité, variabilité des délais, comportement fournisseur), quelle est la distribution complète de demande possible sur le délai d'approvisionnement ?
À partir de cette distribution, on dérive le stock qui couvre votre taux de service cible pour cette référence précise.
Même taux de service, moins de stock
La conséquence pratique n'est pas subtile. Au même taux de service cible, la prévision probabiliste dimensionne moins de stock là où la référence est régulière, et plus de stock là où elle est volatile. Une heuristique fait la moyenne des deux et sur- ou sous-protège chaque côté. C'est pour cela que les équipes qui font tourner un algorithme probabiliste au-dessus de leurs systèmes existants voient le stock baisser et le taux de service monter en même temps. Il n'y a pas d'arbitrage entre les deux.
Les clients de Flowlity réduisent typiquement leurs stocks jusqu'à 40 % avec cette approche. La fourchette dépend du profil portefeuille et du point de départ, mais le mécanisme est le même : remplacer des règles de catégorie par des distributions à la référence.
Une alternative pragmatique : la surcouche probabiliste sur vos systèmes existants
Le DDMRP est une transformation. Mené correctement, il exige le repositionnement des buffers sur le réseau, la refonte des workflows planificateurs, la formation des équipes, et souvent le remplacement ou la reconfiguration substantielle des couches enterprise resource planning (ERP) et Production Planning. Le Demand Driven Institute certifie les praticiens sur plusieurs jours de programme. Les implémentations qui réussissent sont réelles, mais elles ne sont pas légères.
Il existe une voie plus pragmatique. C'est le territoire des Advanced Planning Systems (APS) modernes, la couche qui se pose au-dessus de l'ERP, du MRP ou du DDMRP, et qui prend en charge la logique de planification de bout en bout. Le marché se sépare en deux : les APS legacy bâtis avant que l'IA ne soit largement utilisable (Kinaxis, o9, Blue Yonder, Slim4), et les APS AI-native bâtis directement sur une logique probabiliste (Lokad, Flowlity).
Au lieu de restructurer le modèle de planification, on ajoute une surcouche probabiliste au-dessus des systèmes existants. L'algorithme de prévision produit toujours un plan directeur. L'ERP gère toujours les transactions. Le MRP tourne toujours. Une couche probabiliste de prévision de demande et de stock recalcule le stock de sécurité et les recommandations de réapprovisionnement à la référence, à partir de la distribution réelle de la demande. Le planificateur travaille toujours dans la même interface, juste avec des recommandations plus précises.
Flowlity est une plateforme de planification Supply Chain construite nativement sur l'IA, autour d'une conviction : plus de 95 % du travail d'un planificateur peut et doit être automatisé. L'algorithme produit une prévision probabiliste à la référence, dimensionne dynamiquement les stocks tampons sur la plage d'incertitude, et automatise les décisions de réapprovisionnement routinières. Les planificateurs ne traitent que les exceptions qui nécessitent un arbitrage humain, dans une interface intuitive pensée pour être prise en main directement par les équipes Supply Chain sans formation préalable.
Magotteaux, fournisseur industriel des secteurs ciment et minier, a ajouté une couche probabiliste sur ses systèmes de planification existants plutôt que d'effectuer une transition vers le DDMRP. Les équipes ont réduit leurs stocks de 13 %, leur couverture de 22 % et leurs ruptures de 8 %, sans modifier les systèmes en dessous.
Dans l'agroalimentaire, Danone a digitalisé son réapprovisionnement matières premières et emballages de la même manière : automatisation ajoutée par-dessus la stack de planification existante, plutôt qu'une refonte des systèmes sous-jacents.
Choisir son approche : DDMRP, MRP ou IA probabiliste
Le choix n'est pas « quelle méthodologie gagne ». C'est quelle configuration colle à votre portefeuille, à la maturité de vos équipes et à vos délais.
Le MRP seul, sans buffers ni logique probabiliste, fonctionne dans les environnements stables, à faible diversité et à faible volatilité, où la prévision est suffisamment fiable pour que la nervosité ne pose pas problème. Ce périmètre est devenu plus étroit qu'il y a vingt ans, mais il existe.
Le DDMRP s'adresse aux industriels avec des nomenclatures profondes, des délais longs et une organisation prête à investir dans un changement méthodologique. Il donne le meilleur de lui-même dans les usines de procédé et chez les industriels discrets avec une demande catégorielle stable, là où les hypothèses heuristiques de dimensionnement tiennent bien.
Une approche probabiliste, qu'elle soit en surcouche ou en remplacement, convient aux équipes qui veulent agir sur le risque à la référence plutôt que sur des règles de catégorie. Elle est particulièrement adaptée quand l'équipe vise un déploiement rapide et que le portefeuille comporte des SKU à longue traîne sur lesquels les buffers heuristiques se trompent. Sur les réseaux multi-étages, l'optimisation multi-échelon des stocks coordonne les buffers à travers les niveaux. Un logiciel d'optimisation des stocks piloté par IA s'inscrit dans cette voie.
Lire le DDMRP comme un planificateur devrait
Le DDMRP est un bon diagnostic. Il vise le bon problème (le push piloté par la prévision génère nervosité et sur-protection) et propose une réponse structurée (découpler, bufferiser, gérer par exception). Cela mérite reconnaissance.
Ce que le DDMRP ne fait pas, et que la communication marketing autour de lui zappe le plus souvent, c'est quantifier l'incertitude que ses buffers absorbent. Le facteur de variabilité est une hypothèse de niveau catégorie. Le facteur de délai est similaire. Ce sont des heuristiques défendables, mais ce sont des heuristiques, et c'est la partie la plus exposée quand le portefeuille est creux ou la demande erratique.
Pour les équipes de planification, la question productive n'est pas « faut-il passer du MRP au DDMRP ». C'est de savoir si vos buffers doivent être dimensionnés par règles de catégorie ou par distributions à la référence, et si vous voulez un changement méthodologique sur plusieurs années ou une surcouche probabiliste que vous pouvez déployer maintenant. Les deux voies ont servi des clients. La surcouche probabiliste tend à être plus légère, plus rapide à valeur, et plus simple à concilier avec les investissements ERP et MRP que les équipes utilisent déjà.
Prêt à voir comment Flowlity remplace les règles de catégorie par des buffers probabilistes à la référence ? Demander une démo.
Optimisez votre Supply Chain
grâce à l'IA.
Demander une démo


FAQ
Les réponses aux questions fréquentes
Flowlity vs B2Wise (solution DDMRP) : quelles différences ?
B2Wise est un éditeur proposant une solution basée sur la méthodologie DDMRP (Demand Driven MRP), tandis que Flowlity propose une approche plus flexible de la planification supply chain, enrichie par l'IA.
Analyse comparative : B2wise (DDMRP) vs Flowlity (prévisions probabilistes grâce à l'IA)
B2Wise implémente strictement les principes du DDMRP :
- identification des points de découplage
- calcul des buffers verts/jaunes/rouges
- ajustements des tailles de buffers selon la consommation récente
- etc.
Pour les entreprises qui ont décidé d’adopter le DDMRP comme doctrine de planification, B2Wise fournit un outil spécialisé, conforme au livre « Demand Driven ».
Flowlity, au contraire, n’est pas un outil DDMRP au sens strict, mais il peut intégrer les principes du demand driven de manière plus flexible et intelligente. Voici les différences clés à noter :
Portée méthodologique
B2Wise suit le DDMRP “by the book”, ce qui est parfait si vous voulez appliquer cette méthode rigoureusement.
Flowlity offre une approche plus hybride : vous pouvez définir des points de découplage et des buffers, mais ceux-ci seront recalculés par l’IA de Flowlity en fonction des prévisions probabilistes.
En quelque sorte, Flowlity étend le DDMRP en y ajoutant de la prévision avancée plutôt que de se baser uniquement sur des règles de taille de buffer statiques.
Prévisions vs. positionnement piloté par l’ordre
Le DDMRP, par philosophie, se méfie des prévisions et préfère se baser sur les commandes réelles (demand driven) en ajustant les buffers aux extrêmes.
Flowlity considère que les prévisions, si elles sont bien traitées (de façon probabiliste), apportent une information précieuse pour anticiper. Ainsi, Flowlity va projeter la consommation future pour ajuster les stocks cibles, là où B2Wise va principalement réagir à la consommation effective récente.
Cela donne à Flowlity une longueur d’avance pour les produits où on dispose de signaux de tendance (par exemple, on sait qu’il y aura une promotion ou un lancement à venir – Flowlity en tiendra compte explicitement, alors qu’un pur DDMRP ajustera les buffers après coup).
Adaptabilité
Si vos opérations sortent du cadre du DDMRP pour une partie de votre activité, B2Wise sera moins à l’aise car il est vraiment conçu pour cette logique.
Flowlity est plus généraliste – il peut gérer du demand driven (piloté par la demande) tout en gérant en parallèle du prévisionnel classique pour d’autres flux.
Par exemple, vous pourriez appliquer une logique type DDMRP sur vos composants (avec Flowlity identifiant des buffers sur ces derniers) et une planification prévisionnelle sur vos produits finis – tout dans le même outil.
Cette polyvalence est utile pour des entreprises qui ne veulent pas se restreindre à une seule méthode.
Communauté vs. Innovation AI
B2Wise s’inscrit dans la communauté DDMRP très active (formations, certification, etc.).
Flowlity s’inscrit dans la vague IA appliquée à la supply chain.
Si vous cherchez à capitaliser sur la communauté DDMRP, B2Wise vous fournira l’outil conforme et vous pourrez échanger avec d’autres utilisateurs DDMRP sur les meilleures pratiques.
Si vous cherchez à expérimenter une approche plus novatrice sur vos stocks, Flowlity vous fera bénéficier des dernières avancées algorithmiques (tout en étant DDMRP-compliant sur la notion de découplage, comme mentionné précédemment).
En résumé, choisir B2Wise revient à adopter 100% le standard DDMRP avec un outil dédié, tandis que choisir Flowlity c’est opter pour une solution d’optimisation par l’IA qui peut incorporer du demand driven de façon plus souple.
Pour un adepte puriste du DDMRP, B2Wise sera naturel.
Pour une entreprise qui veut une supply chain data-driven et évolutive, Flowlity apportera une valeur ajoutée en sortant des cadres figés du DDMRP lorsque nécessaire (par exemple, sur les produits très volatils, comme discuté plus haut).
L’idéal est d’analyser vos contraintes : Flowlity peut d’ailleurs simuler un mode DDMRP vs un mode AI pour comparer l’impact sur vos stocks et votre taux de service.
Nos équipes peuvent vous accompagner dans cette réflexion et vous présenter comment Flowlity gère concrètement un scénario DDMRP versus son mode optimisé standard.
Quelle différence entre l'approche de Flowlity et la méthodologie DDMRP ?
Flowlity et le DDMRP (Demand Driven MRP) partagent un objectif commun : mieux positionner les stocks tampons pour absorber les aléas et éviter l’effet bullwhip (coup de fouet) dans la supply chain. Cependant, leur approche méthodologique diffère notablement. Le DDMRP est une méthode déterministe qui définit des buffers de stock à des points de découplage fixes et ajuste ces buffers principalement en fonction de règles prédéfinies (couleurs vert-jaune-rouge en fonction de la consommation par exemple). Cela fonctionne bien pour des produits à demande relativement stable, mais peut montrer ses limites sur des produits à forte volatilité de volume.
Flowlity, de son côté, adopte une approche dynamique et probabiliste : la solution calcule en continu des stocks de sécurité optimisés en se basant sur des prévisions de consommation actualisées et sur l’évaluation de l’incertitude via l’IA . En pratique, Flowlity va ajuster dynamiquement vos stocks tampons en fonction des risques détectés (hausse soudaine de la demande, retard fournisseur) plutôt que de s’en tenir à une taille de buffer figée jusqu’à la prochaine revue. Ceci est une approche « pilotée par les flux » où les buffers sont recalculés fréquemment grâce aux prévisions et à la détection précoce des variations , alors que le DDMRP classique prévoit souvent une révision périodique plus espacée.
À noter que Flowlity identifie aussi les points de découplage critiques dans la chaîne (comme le préconise le DDMRP) afin de découpler la demande et l’offre aux bons endroits, mais la différence est que ces points sont gérés de façon plus intelligente et adaptable grâce au machine learning. En somme, Flowlity reprend l’esprit du demand-driven (pilotage par la demande) tout en y ajoutant la puissance de l’IA pour gagner en réactivité. Les entreprises qui trouvent le DDMRP trop rigide ou manuel apprécieront la capacité de Flowlity à automatiser le recalcul des paramètres (buffers, réapprovisionnements) en continu.
D’ailleurs, selon Flowlity, le DDMRP pur trouve ses limites sur les produits très volatils – c’est justement là que l’approche IA de Flowlity fait la différence en absorbant mieux l’incertitude.
Qu’est-ce que la méthodologie DDMRP (Demand Driven MRP) ?
Le DDMRP (Demand Driven Material Requirements Planning) est une méthodologie qui combine la structure du MRP classique avec des stocks tampons stratégiques positionnés aux points de découplage de la Supply Chain. Le réapprovisionnement est déclenché par la consommation réelle plutôt que par la prévision, ce qui réduit l'effet bullwhip et permet d'ajuster les approvisionnements en temps réel. Chaque buffer est dimensionné en trois zones de couleur (vert, jaune, rouge) à partir d'heuristiques de niveau catégorie pour la variabilité et le délai.
Pour la plupart des industriels mid-market, la question productive n'est pas DDMRP contre MRP classique. C'est de savoir si les buffers doivent être dimensionnés par règles de catégorie ou par distributions probabilistes à la référence. Flowlity remplace les facteurs heuristiques par des distributions de demande complètes apprises à la référence grâce à l'IA, pour que les stocks de sécurité s'adaptent au profil de risque réel de chaque référence. Comparatif complet dans notre guide sur le DDMRP, le MRP et l'IA probabiliste comparés.
DDMRP et IA peuvent-ils fonctionner ensemble ?
Oui, et la combinaison est de plus en plus courante. Le DDMRP fournit le cadre structurel : découplage, buffers, gestion par exception. L'IA probabiliste remplace les facteurs heuristiques au cœur du dimensionnement des buffers par des distributions de demande à la référence et des ajustements dynamiques appris des données. On obtient un modèle de planification de structure DDMRP s'appuyant sur une incertitude mesurée plutôt que sur des règles de niveau catégorie. B2Wise a par exemple ajouté du machine learning au-dessus de sa suite DDMRP-native ; Flowlity a construit l'IA probabiliste comme socle de plateforme et applique une logique de type DDMRP comme un mode parmi d'autres.
Quel est le meilleur logiciel DDMRP ?
Les outils DDMRP-compliants de référence incluent les solutions de SAP IBP, B2Wise, Replenishment+, Intuiflow et Demand Driven Technologies, entre autres. « Meilleur » dépend de votre ERP existant, de la profondeur de votre portefeuille et de votre appétit pour la transformation.
Si l'objectif est la précision des buffers à la référence sans changement méthodologique complet, une plateforme d'IA probabiliste comme Flowlity peut convenir mieux qu'une suite certifiée DDMRP.
Quelle est la durée d'une implémentation DDMRP ?
La plupart des transformations DDMRP durent 6 à 12 mois lorsqu'elles sont menées correctement, avec des programmes plus longs chez les grands industriels. Le chantier comprend la cartographie des points de découplage, la conception des profils de buffers, l'intégration avec l'ERP, la refonte des workflows planificateurs et la formation des équipes.
Une surcouche probabiliste sur les systèmes existants se déploie typiquement en quelques semaines à quelques mois, selon la qualité des données et le périmètre d'intégration.
Le DDMRP convient-il aux industriels mid-market ?
Oui, c'est possible. La méthodologie a été conçue pour des environnements aux nomenclatures profondes et aux délais longs, ce qui correspond à de nombreux industriels mid-market dans les secteurs de procédé et discrets. La contrainte tient à l'effort de mise en œuvre. Le positionnement des buffers, le dimensionnement des profils et la formation des équipes ne sont pas légers.
Les équipes mid-market sans fonction planification dédiée regardent souvent d'abord les surcouches probabilistes, qui offrent un dimensionnement des buffers à la référence sans changement méthodologique complet.
